해당 스터디는 사이버 보안을 위한 머신러닝 쿡북 교재를 기반으로 진행되었습니다.
- 계급 불균형 정의
- 계급 불균형 해결 방안
- 계급 불균형 해결 방안 적용 (실습)
- 요약
계급 불균형 정의
여러 분류/예측 문제에서 자주 마주하게 되는 문제 중 하나가 바로 계급 불균형이다.
분류/예측 문제는 대부분 특정 계급(class, label)으로 분류하거나 예측하게 되는데, 학습 당시에 계급(이하 class) 별로 데이터 양이 매우 불균형할 경우를 계급 불균형(이하 class imbalance)라 부른다.
아쉽게도 실생활 데이터에서 계급 불균형 문제는 자주 발생한다. 예를 들어 사기 탐지(fraud detection), 이상치 탐지(anomaly detection)와 같은 분야나 암 판별이나 악성 코드 탐지와 같이 여러 분야에서 발생하고 있다.
실제로 불균형 문제를 해결하기 위해 여러 방안이 제시되고 있고, 관련 논문도 많이 찾아볼 수 있다. 단편적인 예시로 paperswithcode 에서 class imbalance란 단어로 검색해도 아직까지도 많은 사람들이 고민하고 있다는 것을 알 수 있다.

계급 불균형 해결 방안
대표적인 class imbalance 문제 해결 방안은 아래와 같다.
DownSampling (UnderSampling)
- 데이터가 많은 class(이하 majority)의 데이터를 데이터가 적은 class(이하 minority)의 수만큼 줄이는 방법이다.
- 장점 : 전체적인 데이터셋의 크기가 작아져 전체적인 학습 시간이 줄어들 수 있다.
- 단점 : 단순히 데이터를 삭제하는 것이기 때문에 이로 인한 데이터 손실이 발생할 수 있다.
OverSampling
- Minority 데이터셋의 수를 Majority 데이터셋 수만큼 복제하여 늘린다.
- 장점 : UnderSampling에 비해 데이터의 손실 없이 학습이 가능하다.
- 단점 : 동일한 데이터를 반복해서 사용하기 때문에 Minority 데이터셋에 대해선 과적합 될 수 있다.
Data Augmentation
- Minority 데이터셋과 유사한 데이터셋을 임의로 생성하여 Majority 데이터셋 수만큼 늘린다. (대표적으로 이미지 분류기에서 자주 사용)
- 장점 : UnderSampling에 비해 데이터의 손실 없이 학습이 가능하며, OverSampling에서 발생하는 과적합을 방지할 수 있다.
- 단점 : 데이터를 증식시키는 방법에 따라 결과가 크게 달라지며, 데이터 증식을 진행하는 시간이 추가적으로 발생한다.
단, 위 세 가지 방안은 데이터 측면에서의 불균형 문제를 해결하는 방안이다.
만약 데이터 자체를 수정하기 어려운 경우나 불균형 정도가 심하지 않아 단순히 학습하는 과정에서의 해결 방안을 찾는다면 loss를 계산하는 방식에 class 별로 weight를 부여한다거나(cost-sensitive learning), 모델의 성능 지표를 accuracy가 아닌 f1-score나 weighted accuracy를 활용하는 것도 하나의 방법이 될 수 있다.
※주의※
불균형 문제를 해결하기 위해 Down/OverSampling을 택할 경우, 반드시 Train/Test Set을 나눈 후 Sampling을 진행해야 한다.
특히 OverSampling의 경우 Train/Test Set을 분리하기 전에 Oversampling을 할 경우 Data Leak이 발생하여 성능 측정에 어려움이 발생할 수 있다.
데이터 불균형 문제 해결 방안 적용 (실습)
실습은 위에서 설명한 세 가지 해결 방안을 위주로 진행한다.
(코드는 추후 가독성 높게 업데이트될 예정입니다.)
데이터셋
본 교재에서 제공하는 데이터 셋을 활용한다. 데이터셋과 기본적인 코드는 Packt Github에서 다운로드가 가능하다.
데이터 셋을 대략 살펴보면 아래와 같고, 대략 class의 비율은 9:1로 0이 매우 우세한 것을 볼 수 있다.
데이터 불균형을 해소하기 전과 후의 성능을 비교하기 위해 원데이터에 아무런 전처리를 진행하지 않은 채로 balanced_accuracy(class 별로 정확도(정확히는 recall)를 계산하여 평균을 낸 값) 성능을 확인하면 아래와 같다. 혼동 행렬(Confusion Matrix)을 보면 알 수 있듯이 class 0에 대해서는 예측을 제대로 하고 있으나, class 1에 대한 예측 성능이 상대적으로 떨어지는 것을 볼 수 있다.
OverSampling
데이터 셋의 양이 상대적으로 적은 class 1의 데이터셋을 class 0의 데이터셋의 양만큼 resample을 하여 oversampling을 진행한다.
이후 해당 데이터셋을 활용하여 Decision Tree를 학습하여 예측 결과 및 성능을 확인하면 많이 높아졌음을 확인할 수 있다. 특히 class 1의 예측 성능이 높아진 것이 눈에 띈다.
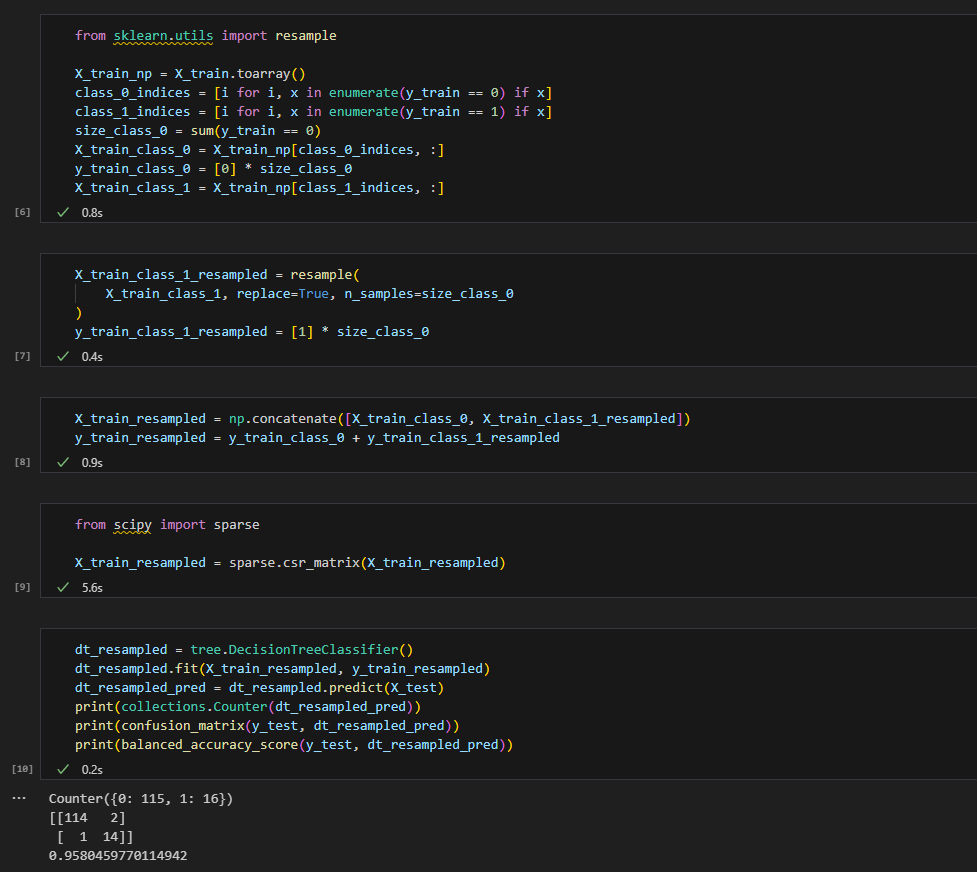
DownSampling
데이터 셋의 양이 상대적으로 많은 class 0의 데이터셋을 class 1의 데이터셋의 양만큼 resample을 하여 downsampling을 진행한다.
이후 해당 데이터셋을 활용하여 Decision Tree를 학습하여 예측 결과 및 성능을 확인하면 많이 높아졌음을 확인할 수 있다. 특히 class 1에 대해서는 전부 제대로 예측하고 있음을 알 수 있다.
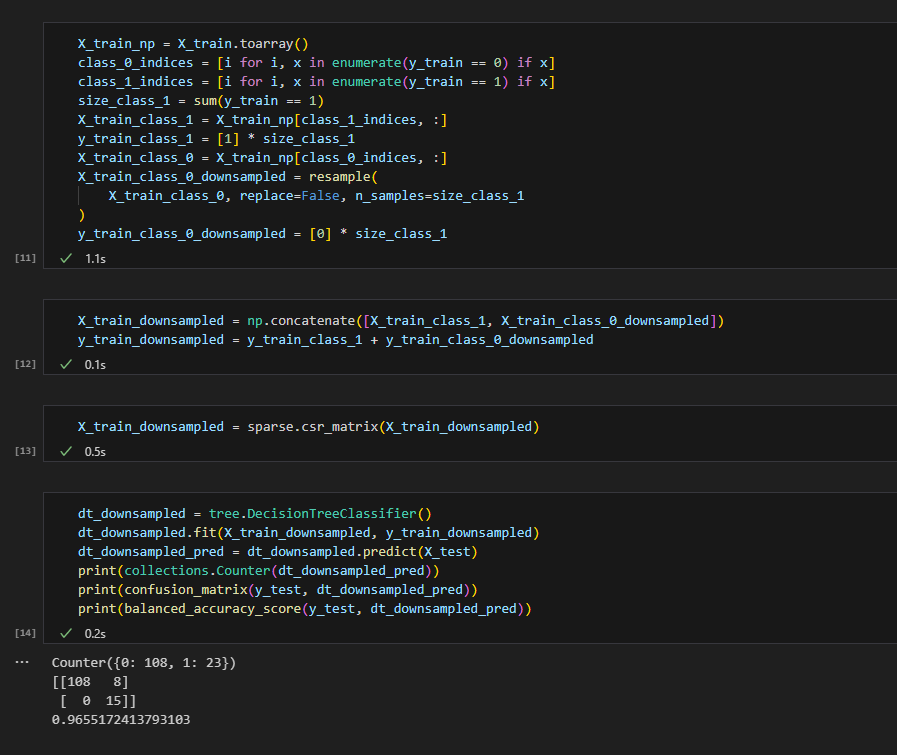
Data Augmentation
데이터 셋의 양이 상대적으로 적은 class 1의 데이터셋을 class 0의 데이터셋의 양만큼 늘리되, 기존의 class 1 데이터셋을 기반으로 신규 데이터를 생성한다.
실습에 사용하는 데이터가 명확히 어떤 데이터인지 드러나있지 않아 데이터 증식을 진행할 방향성을 선정할 수 없었다.
다만 추천하는 데이터 증식 방법은 아래와 같다.
아래 두 가지 방식 전부 데이터 전처리 이전에 진행되어야 한다는 점에서 위의 Down/OverSampling과는 결을 달리하고 있으나 결국은 학습할 데이터의 양을 늘려 보다 고도화된 모델을 만들고자 하는 목표는 동일하다.
이미지 데이터의 추천 방식
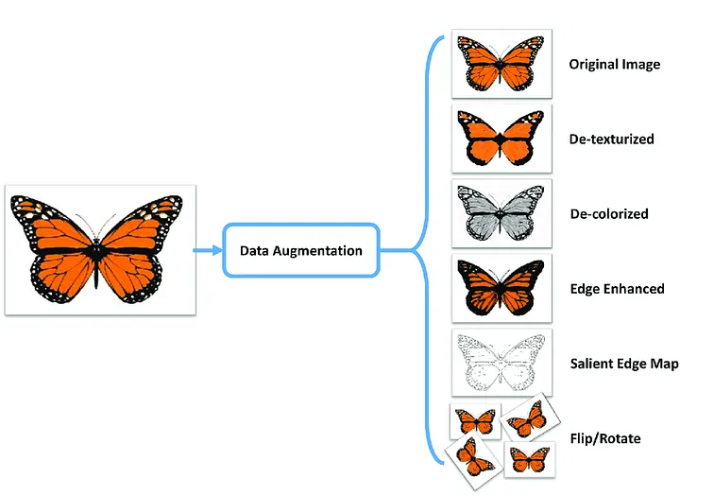
도메인 지식을 활용한 방식
Snorkel이란 라이브러리를 활용하면 아래와 같이 총 3가지 기능을 활용할 수 있다. 여기서 Transformation Function을 활용하면 도메인 지식을 기반으로 데이터를 증식할 방법을 함수화 할 수 있고, 해당 함수를 기반으로 데이터를 증식시킬 수 있다. 상세 예시는 공식 홈페이지에서 확인하는 것을 추천한다.
실제로 현업에서 Snorkel의 Label Function을 활용했었고, 꽤 나쁘지 않은 결과를 확인할 수 있었어서 추후에 좀 더 상세히 다루고 싶은 라이브러리 중 하나이다.
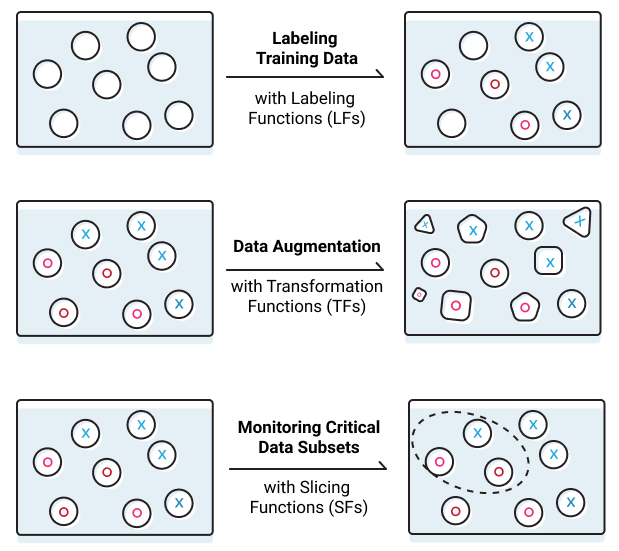
추가적으로 데이터가 아니라 모델에서 학습하는 측면에서 데이터 불균형을 해소할 방안이 있어 실습에서 가볍게 두 가지 더 설명하려고 한다.
모델의 hyper-parameter 활용
해당 실습에서는 Decision Tree의 class_weight를 활용한다. 해당 변수를 통해 class 간의 불균형을 고려해 학습하도록 설정한다. 해당 변수만 추가했을 뿐인데 전반적으로 class 1의 예측 정확도가 높아졌음을 알 수 있다.
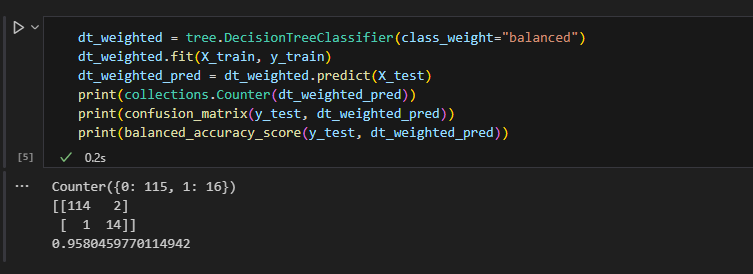
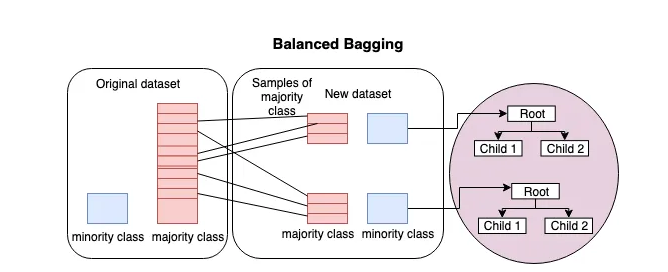
Balanced-Bagging 방식 활용
아래 그림에서 알 수 있듯이, 전체 데이터 셋을 K개로 나눠 각각 Decision Tree(다른 모델을 채택해도 무방)를 학습하는 방식이다. K개로 데이터셋을 나눌 때는 최대한 class 간의 데이터셋의 양이 유사하게끔 맞춰준다.
최종적으로 학습된 K개의 Decision Tree를 Bagging 형식으로 Ensemble 하여 최종적으로 결과를 class를 예측하는 방식으로 다른 방안에 비해 학습 및 예측에 시간이 좀 더 소요될 수 있으나 데이터에 추가적으로 다른 작업을 하지 않아도 모델의 성능을 높일 수 있는 방식이다.
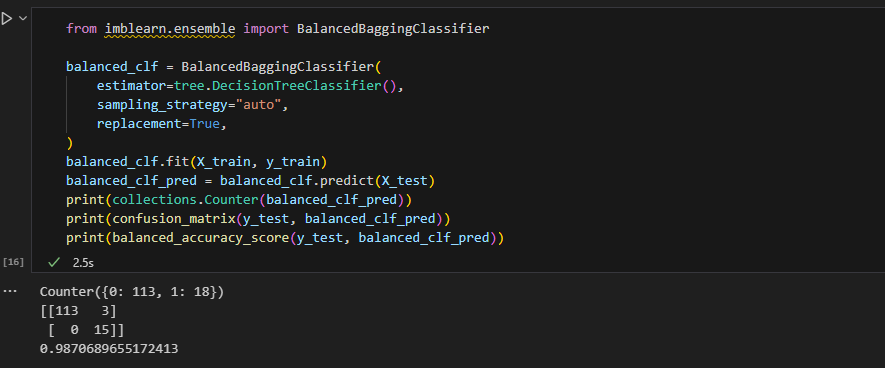
Decision Tree를 활용해 Balanced Bagging을 활용할 경우 아래와 같이 구현할 수 있으며, 최종적으로 어떤 경우보다 가장 높은 성능(balanced accuracy기준)을 보이고 있음을 알 수 있다.
요약
실생활에서 class imbalance한 데이터는 자주 마주하게 되고, 이를 그냥 학습할 경우 데이터 셋이 상대적으로 큰 class에 과대적합할 확률이 매우 높다. 이를 피하기 위해서 데이터 측면과 모델 측면에서의 해결 방안을 살펴보았다.
데이터 측면에서는 Down Sampling, Over Sampling, Data Augmentation이 있었고, 결국 데이터를 줄이거나 늘려 각 class의 비율을 최대한 유사하게 만드는 것에 목적이 있다.
모델 측면에서는 사용하는 모델의 hyper parameter 활용과 Balanced Bagging 방식 활용이 있었다. 학습하는 당시에 class 간의 불균형을 고려하여 loss를 계산한다거나, class의 비율을 최대한 맞추도록 데이터를 쪼개 여러 개의 모델을 학습 및 앙상블하는 방식이었다.
어떤 방식이 더 좋은 성능이 나올지는 테스트를 해봐야 알 수 있고, 만약 불균형 정도가 심하지 않다면 굳이 복잡한 절차를 추가할 필요가 없을 수도 있으니 적용할 데이터를 우선 파악하고, 그에 맞춰 방안을 고려해야 한다는 점을 잊지 말아야 한다.
'데이터 분석 및 학습 > 정보보호 머신러닝 Study' 카테고리의 다른 글
| [MLOps] ML Pipeline (0) | 2023.09.17 |
|---|